“DDPG是Actor-Critic结构的model free & off-policy的方法.”
一、概述
DDPG (Deep Deterministic Policy Gradient)算法是model free(无环境模型), off-policy(产生行为的策略和进行评估的策略不一样)的强化学习算法,且使用了深度神经网络用于函数近似。DDPG可以解决连续动作空间问题,属于actor-critic方法,即既有值函数网络(critic),又有策略网络(actor)。
DDPG算法原文链接:DDPG
二、算法原理
在基本概念中有说过,强化学习是一个反复迭代的过程,每一次迭代要解决两个问题:给定一个策略求值函数,和根据值函数来更新策略。
DDPG中使用一个神经网络来近似值函数,此值函数网络又称critic网络,它的输入是 action与observation [s,a],输出是Q(s,a);另外使用一个神经网络来近似策略函数,此policy网络又称actor网络,它的输入是observation s,输出是action a.
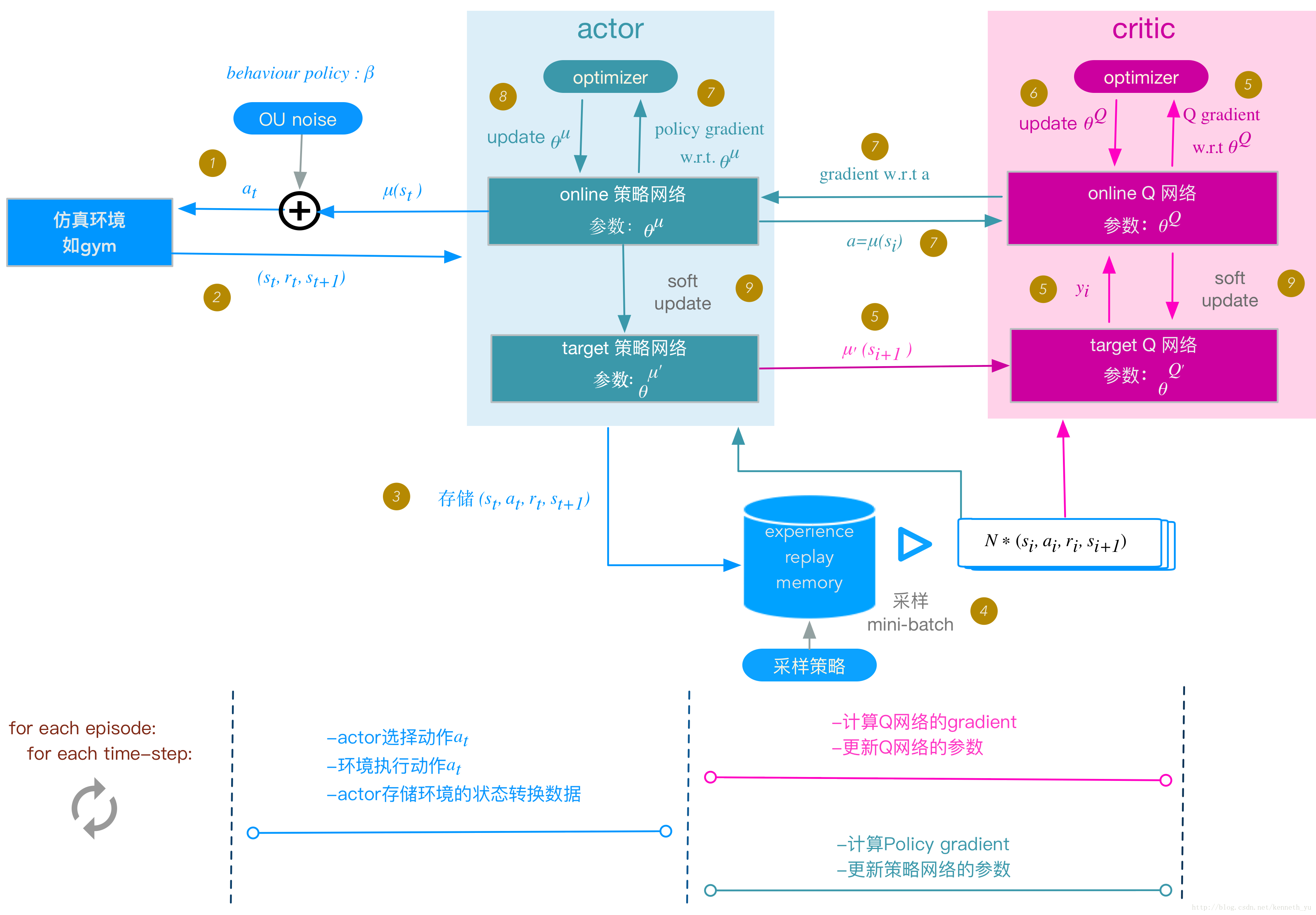 【我还没完。。。】
【我还没完。。。】